数据库设计
译自:https://www.datanamic.com/support/lt-dez005-introduction-db-modeling.html
本文将讲述关系型数据库设计的基础,并解释如何进行良好的数据库设计。文章很长,但我们建议你读完它。数据库设计是相当容易的,但有一些规则需要坚守。知其然更要知其所以然,否则,很容易犯错。
标准化使数据模型更加灵活,从而使处理数据更加容易。请花点时间去学习这些规则,并应用它们。本文使用的数据库是用数据库设计和建�模工具design for Databases设计的。
一个好的数据库设计,首先要列出,你想要保存的数据,以及对其进行的操作。尝试首先用人类语言进行描述,而不要去想 table, column 这些概念。要认真对待这个问题,否则很容易返工。数据库是软件开发中很重要的一部分,值得你多花些时间。
实体 Entities
保存在数据库中的信息,一般称为实体。实体主要包含四种类型:人 (people),物 (things),事件 (events),以及地点 (locations)。如果你发现某种信息不能归入以上四类,那他很可能不是实体,而是实体的属性 (property, attribute)。
让我们使用以下例子,以便于理解。想象,你要创建一个电商网站,都需要处理哪些信息呢?在一家商店 (shop),你做的事情,是出售商品 (products),给顾客 (customers)。
- 商店 shop,是一个 location.
- 出售 sale,是一个 event
- 商品 products,是 things
- 顾客 customers,是 people 以上就是所有需要数据库需要包含的全部的实体。
在交易过程中,还有别的事情发生吗?一个顾客走进商店,靠近一名售货员(vendor),问了一个问题,得到一个答案。售货员也参与了这个过程,并且是 people,所以我们需要一个售货员实体。
Figure 1: Entities: type of information.

关系 Relationships
下一步是确定实体之间的关系,以及每个关系的基数(Cardinality)。关系是实体间的联系,跟真实世界类似:一个实体会对另一个实体做什么?他们之间有什么关系?比如顾客 (customers) 购买 商品 (products),商品被卖给顾客,一次出售 (sale),包含若干商品,并发生在一家商店 (shop)
基数(cardinity) 表达的是关系两端实体间的数量对比。对于每一个关系,你都要先声明,左侧的一个实体,能包含多少个右侧的实体。比如:一次出售,能有多少顾客呢?一个顾客,能属于多少次出售活动?一个商店,能发生多少次出售?
你将会有如下结论: (请注意,商品 product 代表某一种类的商品,而不是某一个特定商品)
- Customers --> Sales; 一个顾客可以多次进行购买
- Sales --> Customers; 一次出售活动,只属于一名顾客
- Customers --> Products; 一个顾客可以购买多种商品
- Products --> Customers; 一个商品可以被多名顾客购买
- Customers --> Shops; 一个顾客可以到多个商店进行购买
- Shops --> Customers; 一个商店可以接待多名顾客
- Shops --> Products; 一个商店有多种商品
- Products --> Shops; 一类商品可以在多个商店进行售卖
- Shops --> Sales; 一个商店可以进行多次售卖
- Sales --> Shops; 一次售卖只能发生在一家商店
- Products --> Sales; 一类商品可以多次被出售
- Sales --> Products; 一次售卖可以包含多种商品
如何确定我们已经包含了所有关系呢?共有四种实体,每种实体与其他三种实体之间,都有关系。所以共有 4*3 = 12 种关系。
接下来让我们进行汇总,来找到整�体关系的基数。为了实现这个目的,我们首先列出每一种关系的基数。为了使这个过程变得简单,我们会对箭头进行调整,改变其方向:
- Customers --> Sales; 一个顾客可以多次进行购买
- Sales --> Customers; 一次出售活动,只属于一名顾客
我们会改变第二个关系的方向,让实体顺序保持一致。
- Customers <-- Sales; 一次出售活动,只属于一名顾客
基数有四种类型:一对一,一对多,多对一,多对多。在数据库设计中,这表示为:1:1,1:N, M:1,和 M:N。
- Customers --> Sales; 一个顾客可以多次进行购买;1:N
- Customers <-- Sales; 一次出售活动,只属于一名顾客;1:1
最终的基数,便是左右两侧分别分配最大数,其中,N 和 M 都大于 1。上述关系中,两种情况左侧都是 1,右侧则分别为 1 和 N,N 是最大值。所以基数为 1:N。一个顾客可以进行多次购买,但是一次购买只属于一名顾客。
让我们为其他关系也进行类似计算,得到:
- Customers --> Sales; --> 1:N
- Customers --> Products; --> M:N
- Customers --> Shops; --> M:N
- Sales --> Products; --> M:N
- Shops --> Sales; --> 1:N
- Shops --> Products; --> M:N
最终,我们将会有两个 一对多 关系,以及四个 多对多 关系。
Figure 2: Relationships between the entities.
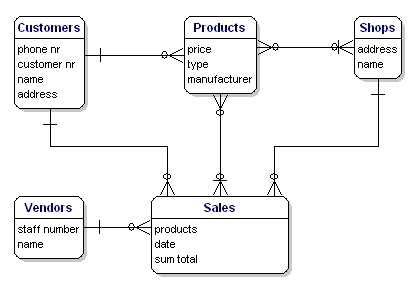
实体之间可能会有互相依赖。这意味着,如果某一个条目不存在,那么令一个条目也不可能存在。比如,如果没有顾客,那么便不可能有销售;如果没有商品,也不会有销售。
销售 ---> 顾客,销售 ---> 产品 这两种关系是强制依赖,反过来则不然。即使没有销售,顾客、产品也可以存在。这对接下来的内容很重要。
递归关系 Recursive Relationships
有时候,一个实体会拥有指向自己的关系。比如,一名 empolyee 拥有一个 boss,而 boss 本身也是一名 employee。employees 实体的 boss 属性(attribute) 指向 employees 实体
在一个 ERD 中,这种关系表现为从实体中出发的线条,返回到当前实体。
冗余关系 Redundant Relationships
有时候你的数据模型中存在冗余关系。这是一种已经在其他关系中间接包含的关系。
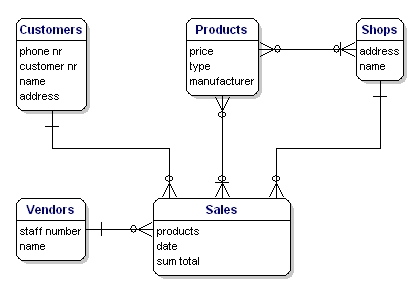
在我们的例子中,顾客和产品有直接关系。但是 顾客与销售、销售与产品之间,也有关系。其中便包含了顾客与产品之间通过销售的间接关系。Customers <----> Products 关系出现了两次,其中之一就是冗余关系。在这个例子中,产品只会通过销售被购买所以 Customers <----> Products 的直接关系应该被删除。之后,数据模型如下:
Figure 3: Relationships between the entities.
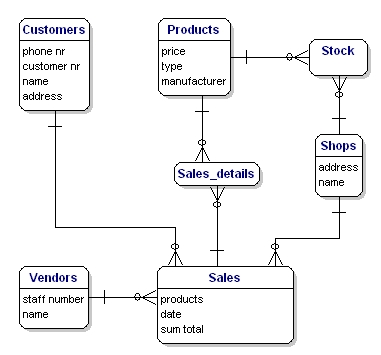
处理多对多关系
在数据库中,我们没法直接实现多对多 (M:N) 关系。 多对多关系意味着,一张表中的若干条记录,属于另一张表中的若干条记录。需要另寻他处来存储这些关系,一般解决方案是将其分成两组一对多的关系。
可以通过在两组实体间,创建一张新表来实现。在我们的例子中,销售与产品间是多对多关系,我们为此创建一个新实体:sales-products。这个实体同时与销售、产品具有多对一的关系。从逻辑模型层面,这被称为关联实体(associative entity);而在物理数据库术语中,这被称为链接表、交集表或联结表(link table, intersection table or junction table)。
Figure 4: Many to many relationship implementation via associative entity.

![]()
除了 Products <----> Sales,另一个需要解决的多对多关系是 Products <----> Shops。这两种情况,我们都需要创建新实体,但这个新实体应该如何命名呢?
对于 Products <----> Sales 关系,每次销售包含多种产品。这个关系展示了销售的内容或者说销售的细节。所以可以称之为 销售细节(Sales details),你也可以称之为 卖掉的产品(sold products)。
Products <----> Shops 关系则展示了商店中可以购买的产品,也就是库存(sock)。
我们的数据模型如下:
Figure 5: Model with link tables Stock and Sales_details.
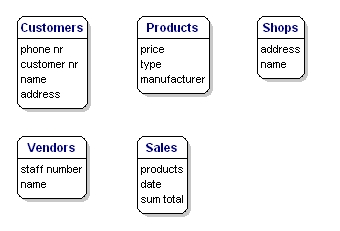
属性 Attributes
每个实体中,我们想保存的数据,便是其属性。 对于产品,我们两了解的是价格、制造商、型号。对于顾客,是顾客编号、姓名、地址。对于销售,是什么时候发生、在哪个商店,包含哪些产品,以及总价。对于服务员,是员工号码、姓名、地址。具体的内容现在不重要,只是要列出你想保存的条目。
Figure 6: Entities with attributes.
衍生数据 Derived Data
已经保存在现有其他数据中的数据,我们称之为衍生数据。在这个例子中,总价格便是一例。已知销售中的每一项售出内容和价格,所以很方便计算出总价。所以没必要存储总价。
那为什么还要存储呢?因为这是一次销售,而产品的价格可能会有变化。一个产品可能今天卖 10 欧元,下个月卖 8 欧元。对于管理者,需要知道销售发生时的具体价格,最简单的方法,便是将其存储。当然,有一些更优雅的办法,不过不在本文讨论之列。
展示实体和关系: 实体关系图 Entity Relationship Diagram (ERD)
实体关系图提供数据库的整体预览,有几种类型和样式。比较常见的一种是 crowfeet 表示法,其中实体表示为矩形,关系表示为实体之间的线,线末端的样式表示关系的类型。强制关系通过破折号表示出来,非强制性实体通过圆圈表示。多 则通过 crowfeet 来表示,表示关系的线一分为 3。
一对一的强制关系如下:
Figure 7: Mandatory one to one relationship.
![]()
一对多的强制关系如下:
Figure 8: Mandatory one to many relationship.
![]()
多对多关系如下:
Figure 9: Mandatory many to many relationship.

我们例子中的数据模型如下:
Figure 10: Model with relationships.
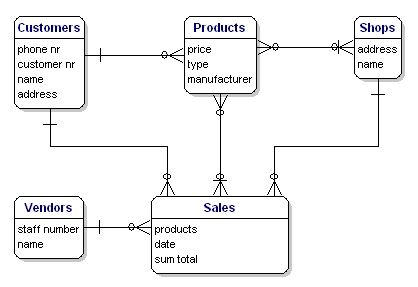
分配键 Keys
主键 Primary Keys (PK)
主键是可以唯一标识一条实体的一个或多个属性。包含两个以上属性的键被称为组合键。主键的所有属性都不能为空,并且这些属性组成的值在表中必须是唯一的。
在我们的例子中有一些很明显的适合做主键的属性。顾客都有编号,产品都有独特的产品编号,销售也都有其编号。这些数据都是唯一的,并且每条记录都包含,所以可以做主键。一般我们用整数(integer)列作为主键,这样可以让通过主键检索数据变得容易。
链接实体(Link-entities)通常指向他们链接的实体的主键。链接实体的主键通常是这些引用属性的集合。比如,对于 Sales_details 实体,我们可以用 sales 和 products 的主键组合作为其主键。通过这种方式,我们可以确保一次销售中,对于特定产品,只能包含一次。
在 ERD 中,主键通过名称后面的<PK> 来表示。在我们的例子中,只有商店没有特别适合做主键的属性。为此,我们引入一个新的属性:shopnr。
外键 Foreign Keys (FK)
外键,是被当前实体引用的实体的主键。在 ERD 中,通过名称后面的 <FK> 来表示。外键也可以同时作为主键,此时用 <PF> 来表示。这种情况一般出现在链接表,因为对于两个实体,通常只需要链接一次。(在一次销售中,一个特定品类的产品只能被卖一次。)
添加键的标识之后,我们的数据模型将如下所示。值得注意的是,sales 表中不再需要 products,因为将会出现在 sold products 链接表中。与此同时,我们在链接表中添加了一个新的属性,数量 quantity。我们也在 stock 表中添加了这个属性,用以表示库存量。
Figure 11: Primary keys and foreign keys.
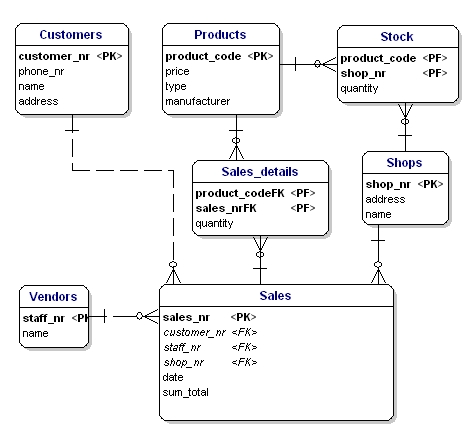
属性的数据类型
接下来需要决定的是属性的属性的数据类型。数据类型有很多,一些是标准的,另一些则是特定数据库特有的。一些数据库还可以自定义类型。
每个数据库都有的标准类型如下:CHAR, VARCHAR, TEXT, FLOAT, DOUBLE, and INT.
Text:
- CHAR(length) - 包含特定数量的字符 (characters, numbers, punctuations...). 比如 CHAR(10) 最多保存 10 位。但如果你只使用了两位,数据库依然会保存 10 位。剩余的 8 位将为空。
- VARCHAR(length) - 包含字符,与 CHAR 类似,唯一区别是 VARCHAR 只占用必须得空间。
- TEXT - 可以包含大量字符,取决于所用的数据库,甚至可能上 G。
Numbers:
- INT - 包含一个正整数或负整数。许多数据库对其进行了扩展,比如 TINYINT, SMALLINT, MEDIUMINT, BIGINT, INT2, INT4, INT8。这些扩展相比于 INT,只改变了数字的位数。 INT 包含四字节 (INT4) ,适用于从 -2147483647 到 +2147483646 的数字。或者你也可以定义为无符号,用以表示 0 to 4294967296。INT8 或者 BIGINT,适用于更大的范围,从 0 到 18446744073709551616,于此同时,占用更多的空间,即使只是保存很小的数字。
- FLOAT, DOUBLE - 与 INT 类似,可以用于保存浮点数。请注意,有时候他们工作并不如你的预期。比如,MySQL 对浮点数的计算并不完美,
(1/3) * 3得到的值将会是 0.9999999,而不是 1。
其他类型:
- BLOB - 二进制数据,比如文件。
- INET - 用以 IP 地址,以及子网掩码。
添加类型后,我们的数据模型如下:
Figure 12: Data model displaying data types.
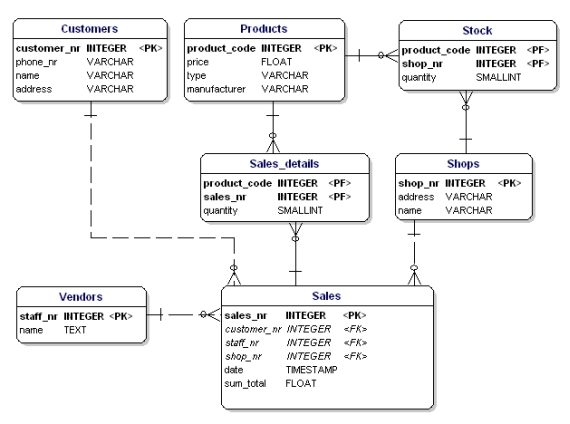
规范化 Normalization
规范化使数据模型灵活可靠。这会带来一些额外的开销,因为通常需要更多的表,但他也让你在无需调整数据库的情况下,可以做更多的事情。扩展阅读:this article。
第一种形式
第一种形式的规范化指出,实体中的列不可以重复。我们可以创建一个实体“sales”,其中包含所购买的每个产品的属性。它看起来是这样的:
Figure 13: Not in 1st normal form.

这里面的错误在于,只有三种产品可以被售卖。如果你想售卖第四种产品,需要启动另一次销售,或增加一个属性 product4。这两种方法都不好。我们应该创建一个新的实体,并通过一对多的关系进行链接。
Figure 14: In accordance with 1st normal form.
第二种形式
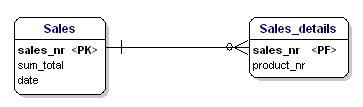
第二种形式指出,实体的所有属性,都应该依赖主键。这意味着实体的每个属性只能通过整个主键来标识。假设我们在Sales_details实体中有日期:
Figure 15: Not in 2nd normal form.

这个实体不符合第二个规范化形式,因为为了能够查询销售日期,我不需要知道销售了什么(productnr),只需要知道销售编号。通过将表分为 sales 和 Sales_details 来解决:
Figure 16: In accordance with 2nd normal form.
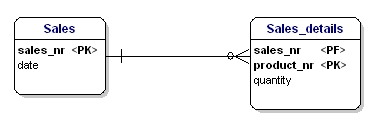
现在,实体的每一个属性,都只依赖于主键。日期只依赖于销售编号,数量依赖于销售编号以及销售的产品。
第三种形式
第三种形式指出,所有属性都应该直接依赖于主键,而不是其他属性。这看起来与第二种形式类似,事实确是相反。在第二种形式的规范化中,我们通过PK指出属性,在第三种形式的规范化中,每个属性都需要依赖于PK,而不是其他。
Figure 17: Not in 3rd normal form.

在上例中,产品价格依赖于订单编号,订单编号则依赖于销售编号和产品编号。这不符合第三种形式。同样,拆分表格来解决。
Figure 18: In accordance with 3rd normal form.
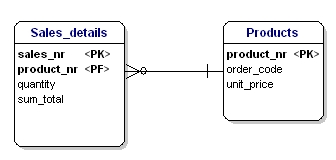
更多的形式
除了上述三种,规范化还有更多形式,但普通用户无需关心。其他形式更适用于特定应用。只需要遵从上述三种规范化,便可适用于大多数程序。
正规化的数据模型
使用正规化规则,我们会发现,product 中的 manufacturer 也需要一张单独的表。
Figure 19: Data model in accordance with 1st, 2nd and 3d normal form.
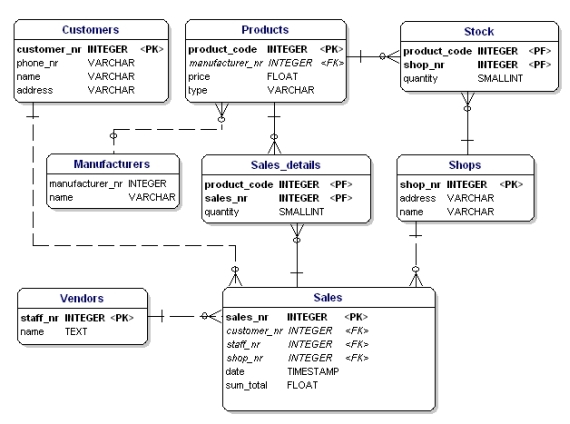
词汇 Glossary
- 属性 Attributes -实体的具体数据,比如价格、长度、名称。
- 基数 Cardinality - 两种实体间的关系,用数字表示。比如,一个人可以有多个订单。
- 实体 Entities - 抽象后��的数据,存储在数据库中。比如,顾客,产品。
- 外键 Foreign key (FK) - 对于另一张表中主键的引用。外键列只能包含其引用的主键列中存在的值。
- 键 Key - 键用来指向其他记录。最常见的是主键。
- 规范化 Normalization - 一个灵活的数据模型需要遵循若干规则。应用这些规则的过程,被称为规范化
- 主键 Primary key - one or more columns within a table that together form a unique combination of values by which each record can be pointed out separately. For example: customer numbers, or the serial number of a product.
Resources
Learn
- DeZign for Databases: Learn more about DeZign for Databases.
- Database normalization: Learn how to normalize a data model (1NF, 2NF, 3NF).
- Getting started with DeZign for Databases: Start making a data model directly.
- Display data types in a diagram: Learn how to display data type and/or domain info in the entity boxes on your diagram.
Get products and technologies
- Build your next data model with DeZign for Databases trial software, available for download directly from Datanamic's download section.
- Need (realistic) test data for your new database? Try out our data generator.